
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- hackctf
- BOJ Python
- lob
- 풀이
- 숙명여자대학교 정보보안 동아리
- 머신러닝
- HTML
- CSS
- The Loard of BOF
- 백준
- PHP 웹페이지 만들기
- SWEA
- c++
- Sookmyung Information Security Study
- Python
- siss
- 생활코딩
- C언어
- XSS Game
- c
- 파이썬
- 웹페이지 만들기
- BOJ
- 기계학습
- 숙명여자대학교 정보보안동아리
- 드림핵
- 자료구조 복습
- Javascript
- WarGame
- hackerrank
- Today
- Total
혜랑's STORY
[정리] 기계학습(Machine Learning, 머신러닝)은 즐겁다! Part 3 본문
[정리] 기계학습(Machine Learning, 머신러닝)은 즐겁다! Part 3
hyerang0125 2021. 9. 5. 00:25딥러닝(Deep Learning)과 컨볼루션 신경망(Convolution Meural Network 또는 CNN)

이 웹툰은 3살짜리 아이는 새의 사진을 쉽게 인식 할 수 있어도, 50년 이상 최고의 컴퓨터 과학자들은 컴퓨터로 객체를 인식하는 방법을 알아내기 위해 노력했으나 불가능했다는 것을 보여준다.
그러나 지난 몇 년 사이, 딥 컨볼루션 신경망(deep convolutional neural networks)을 사용해 드디어 객체 인식에 대한 좋은 접근 방법을 발견했다.
#1. 심플하게 시작
새의 사진을 인식하는 방법을 배우기 전에, 손으로 쓴 숫자 "8"과 같은 좀 더 심플한 것을 인식하는 방법을 알아보자.
Part 2에서는 단순한 뉴런(neuron)을 많이 연결함으로써 신경망(neural network)이 어떻게 복잡한 문제를 해결할 수 있는지에 대해 배웠다. 그리고 얼마나 많은 침실이 있는지, 얼마나 큰지, 어느 동네에 있는지에 따라 집의 가격을 추정할 수 있는 작은 신경망을 만들었다.

또한 기계 학습이라는 아이디어는 동일한 일반 알고리즘을 다른 데이터로 재사용해서 다른 종류의 문제를 해결할 수 있다는 것을 알고 있다. 그럼 필기체를 인식하기 위해 위 신경망을 수정해 보자. 그러나 정말 심플하게 만들기 위해, 하나의 글자인 숫자 "8"만을 인식 해볼 예정이다.
기계 학습은 데이터가 있을 대 그것도 아주 많이 있을 대 잘 동작한다. 그래서 손으로 쓰여진 "8"이 정말 많이 필요하다. 다행이도, 연구자들이 이와 같은 목적을 위해 필기체 숫자의 MNIST 데이터 세트를 만들었다. MNIST는 하나 당 18x18 픽셀 크기의 이미지로 60,000개의 필기체 숫자 이미지들을 제공한다.

생각해보면 우리는 신경망으로 이미지를 처리하려고 한다. 신경망은 숫자를 입력으로 사용하고, 컴퓨터에서 이미지는 실제로 각각의 픽셀이 얼마나 어두룬지를 나타내는 숫자 그리드일 뿐이다.
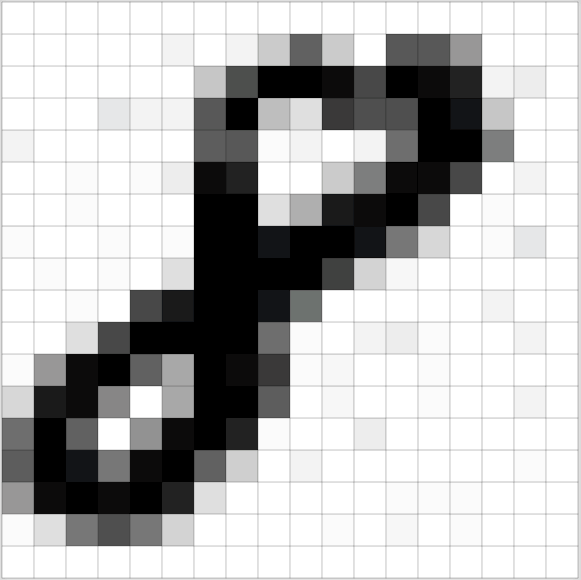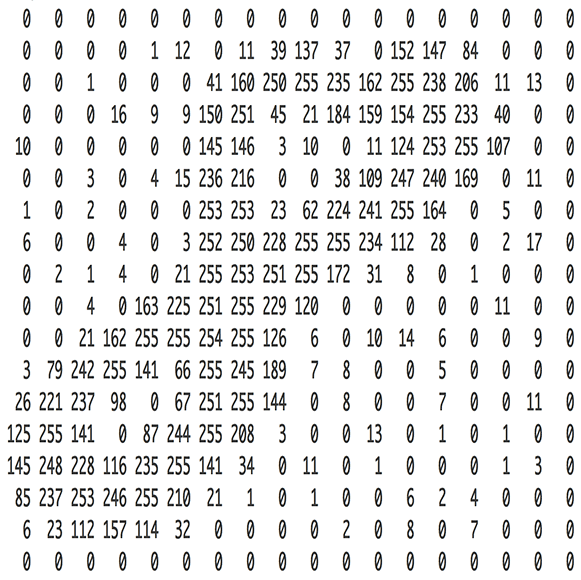
신경망에 이미지를 공급(feed)하기 위해서는, 먼저 간단히 18x18 픽셀 이미지를 324개의 숫자들의 배열로 생각한다.

324개의 입력을 처리하기 위해, 신경망은 324개의 입력 노드를 갖도록 변경하기만 하면 된다.
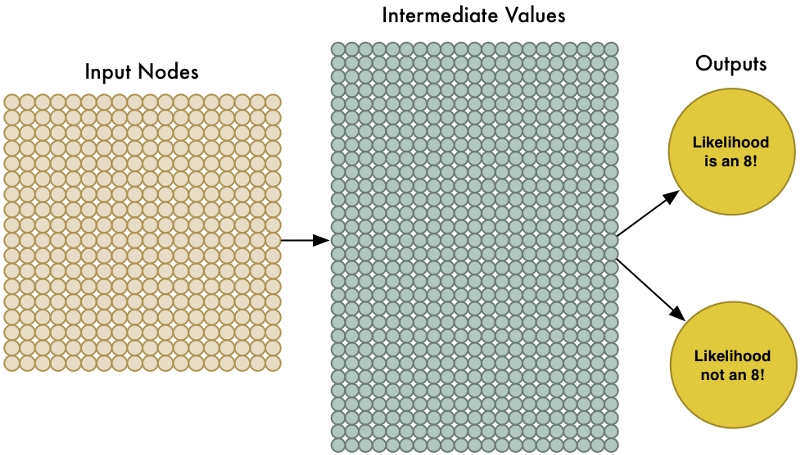
신경망에는 두 개의 출력이 있다. 첫 번째 출력은 이미지가 "8"일 가능성이고 두 번째 출력은 "8"이 아닐 가능성이 예측하는 것이다. 인식하려는 개별 객체에 대해 별도의 출력을 가짐으로써 객체를 그룹으로 분류 할 수 있다.
이제 신경망을 "8"과 "8"이 아닌 이미지로 훈련시켜서 이를 구분할 수 있게 하는 것이 남았다. 만약 "8"을 제공(feed) 할 때 그 이미지가 "8"일 확율은 100%이고 "8"이 아닌 확률은 0%가 되어야 한다.
다음은 우리의 훈련 데이터이다.

훈련이 끝나면 "8"이라는 그림을 꽤 높은 정확도로 인식 할 수 있는 신경망을 갖게 될 것이다. 특히 글자가 이미지 중간에 있는 단순한 이미지에서는 잘 작동한다.

그러나 문자가 이미지의 중심에 완벽하게 맞지 않으면 전혀 동작하지 않는다. 아주 약간 위치만 바뀌어도 작동 x

그 이유는 신경망이 "8"이 완벽하게 중심에 있는 패턴만을 배웠기 때문이다. 이런 것은 현실 세계에서 전혀 쓸모가 없다. 따라서 이러한 경우에도 신경망을 동작시킬 방법을 알아내야 한다.
무차별 대입(Brute Force) 아이디어 #1. 슬라이딩 윈도우(Sliding Window)로 찾기
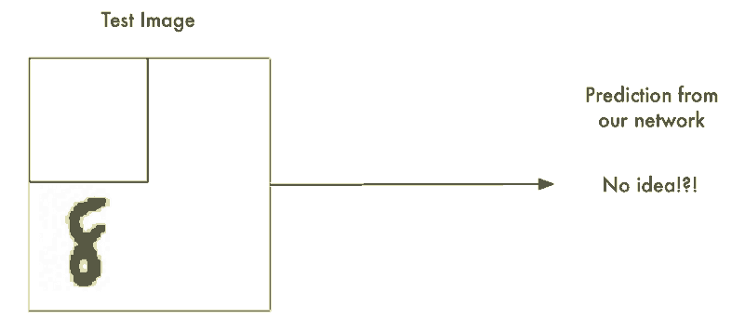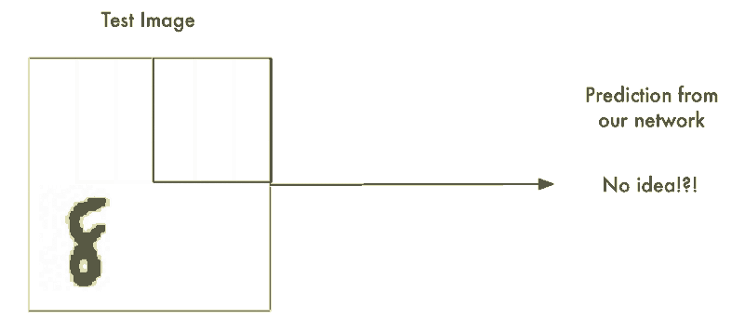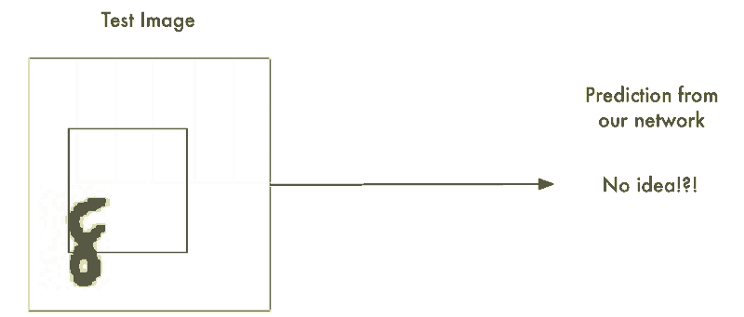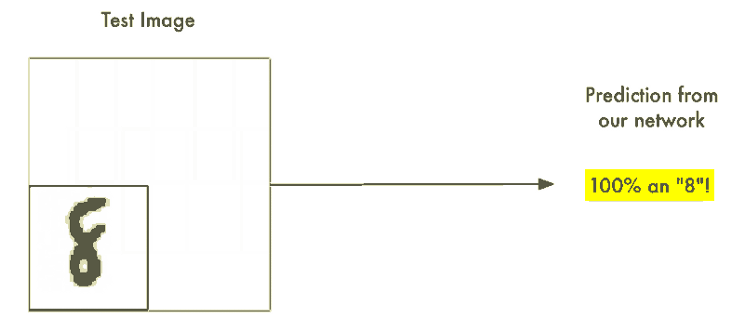
이 접근 방식을 슬라이딩 윈도우(sliding window)라고 한다. 또한 이것은 무차별 대입(brute force) 솔루션이다. 일부 제한된 경우에는 잘 동작하지만 실제로는 매우 비효율적이다. 다양한 크기의 객체를 찾기 위해 같은 이미지를 계속해서 확인해야 한다.
무차별 대입(Brute Force) 아이디어 #2. 더 많은 데이터와 딥 신경망(Deep Neural Net)
앞서 신경망을 훈련시킬 때, 완벽하게 중앙에 위치한 "8"만을 보여주었다. 그렇다면 이미지 안에 여러 크기의 다른 위치에 있는 "8"에 대한 더 많은 데이터로 훈련시키면 된다.

이미 가지고 있는 훈련 이미지의 다른 버전을 만들어서 합성 훈련 데이터(Synthetic Training Data)를 만들었다.
이러한 테크닉을 통해 우리는 훈력 데이터를 손쉽게 무한정 공급할 수 있다.
데이터가 많을수록 당연히 신경망이 해결하기는 어려워진다. 그러나 네트워크를 더 크게 만들어 더 복잡한 패턴을 배울 수 있도록 함으로써 이를 보완할 수 있다.
신경망을 크게 만들기 위해서 단지 노드의 레이어를 중첩하면 된다.
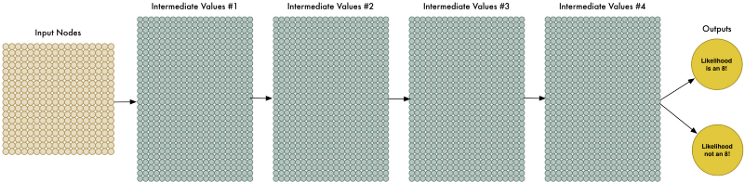
전통적인 신경망(traditional neural network)보다 더 많은 계층(layers)을 가지고 있기 때문에 이것을 "딥 신경망(deep neural network)"라고 부른다.
생각해보면 "8"이 그림의 어느 위치에 있더라도 추가적인 훈련 없이 같은 것이라고 인식할 만큼 충분하게 현명한 신경망을 만들 방법을 찾아야 한다.
#2. 컨볼루션(Convolution)
현재 신경망은 이미지의 다른 부분에 있는 "8"을 서로 완전히 다른 것이라 생각한다. 그림상에서 어떤 객체를 움직인다고 해서 바뀌는 건 없다는 것을 이해하지 못하는 것이다. 이러한 경우 가능한 모든 위치에서 각 객체를 식별하는 것을 모두 다시 학습해야 한다.
"8"은 그림에서 어디에 나타나더라도 "8"이라는 이동 불변성(translation invariance)을 신경망이 이해하도록 해야 한다.
컨볼루션(Convolution)의 동작 방식
신경망에 전체 이미지를 한개의 그리드로써 전체 이미지를 공급(feed)하는 대신에, 객체는 그림의 어디에서 나타나더라도 동일한 것이라는 아이디어를 활용할 것이다.
Step 1: 이미지를 중첩된 이미지 타일들로 나누기
앞선 슬라이딩 윈도우 검색과 유사하게, 원본 이미지 전체에 슬라이딩 윈도우를 적용해서 각 결과를 별도의 작은그림 타일로 저장한다.

이렇게 해서, 원본 이미지를 동일한 크기의 작은 이미지 타일 77개로 변환했다.
Step 2 : 각 이미지 타일을 작은 신경망에 제공(feed)하기
앞서 하나의 이미지를 신경망에 제공(feed)한 것과 같은 작업을 진행한다. 다만 각 개별 이미지 타일에 대해 이 작업을 수행한다.

한 가지 중요한 점은 동일한 원본 이미지의 모든 단일 타일에 대햏 동일한 신경망 가중치(same neural network weights)를 유지해야 한다는 것이다. 다시 말해서, 모든 이미지 타일을 동일하게 취급하고 어떤 타일에 무엇인가 흥미로운 것이 나타나면, 그 타일을 흥미있는 것이라고 표시 할 것이다.
Step 3 : 각 타일에 대한 결과를 새로운 배열에 저장하기
원본 타일의 배열(array) 형태를 버리고 싶지 않기 떄문에 각 타일을 처리한 결과를 원본 이미지에 대한 동일한 배열 형태로 그리드에 저장한다.

하나의 큰 이미지로 시작해서 원래 이미지의 어느 부분이 가장 흥미로운지를 기록한 조금 크기가 작아진 배열을 얻게 되는 것이다.
Step 4 : 시료 채취하기
step 3의 결과는 원본 이미지의 어느 부분이 가장 흥미로운지를 나타내는 배열이었다. 그러나 이 배열도 여전히 너무 크다.

배열의 크기를 줄이기 위해서, 맥스-풀링(max pooling)이라는 알고리즘을 사용해서 시료를 채취한다.
단순히 결과 배열을 2x2 정사각형으로 나누어 각각에서 가장 큰 숫자만을 취합한다.

이 아이디어는 각 2x2 사각형 격자(square grid)를 구성하는 4개의 입력 타일에서 흥미로운 것을 찾으면, 가장 흥미로운 것을 유지할 수 있다는 것이다. 이를 통해 가장 중요한 부분을 유지하면서도 배열의 크기를 줄일 수 있다.
Final Step : 예측하기
지금까지 커다란 이미지의 크기를 상당히 작은 배열로 줄였다. 이제 이 작은 배열을 다른 신경망에 제공할 입력으로 사용할 수 있다. 그리고 그 신경망이 이미지가 일치하는지 또는 일치하지 않는지를 결정해 줄 것이다. 앞선 컨볼루션 단계(step)들과 구분하기 위해 이를 "완전히 연결된 망(fully connected network)"이라 부른다.

#3. 더 많은 단계를 추가하기
이미지 처리 경로(pipeline)는 다음과 같은 일련의 단계들로 이루어진다: 컨볼루션(convolution), 맥스-풀링(max pooling), 완전히 연결된 망(fully-connected network)
기본 아이디어는 큰 이미지로 시작해서 마지막으로 하나의 결과가 나올 때까지 단계적으로 반복해서 데이터를 압축해 가는 것이다. 더 많은 컨볼루션 단계를 가져갈 수록, 신경망은 학습을 통해 더욱 복잡한 형상을 인식할 수 있다.
현실적인 딥 컨볼루션 망은 다음과 같다.

224x224 픽셀 이미지에서 시작해서, 컨볼루션과 맥스 풀링을 두번 적용한 다음 컨볼루션을 추가로 3번 더 적용한다. 그리고 다시 맥스 풀링을적용한 다음 두 번의 완전히 연결된 망의 단계(layers)를 적용한단. 최종 결과는 이미지가 1000개의 범주 중 하나로 분류되는 것이다.
정확한 신경망을 구축하기 위해서는 많은 실험과 테스트를 통해서 신경망을 훈련시켜야 한다.
#4. 새 분류기 만들기
이제 사진이 새인지 아닌지를 결정할 수 있는 프로그램을 작성할 수 있다.
항상 그렇듯이 시작하기 위해서는 데이터가 필요하다.
합친 데이터 세트에 있는 새들 사진 중 일부 :

52,000장의 새가 아닌 사진 중 일부

이 데이터 세트는 목적에 맞게 잘 동작하겠지만, 72,000개의 저해상도 이미지는 현실 세계의 애플리케이션에 사용하기에는 여전히 작은 데이터이다. 높은 성능을 위해서는 수백만 개의 고해상도 이미지가 필요하다.
새 분류기를 만드릭 위해 TFLearn을 사용할 것이다. TFlearn은 단순화 된 API를 제공하는 Google의 TensorFlow 딥러닝 라이브러리의 래퍼(wrapper)이다. 이를 이용하면 신경망 계층을 저의하는데 단 몇 줄의 코드만 작성하면 된다.
신경망을 정의하고 훈련시키기 위한 코드
# -*- coding: utf-8 -*-
"""
Based on the tflearn example located here:
https://github.com/tflearn/tflearn/blob/master/examples/images/convnet_cifar10.py
"""
from __future__ import division, print_function, absolute_import
# Import tflearn and some helpers
import tflearn
from tflearn.data_utils import shuffle
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.estimator import regression
from tflearn.data_preprocessing import ImagePreprocessing
from tflearn.data_augmentation import ImageAugmentation
import pickle
# Load the data set
X, Y, X_test, Y_test = pickle.load(open("full_dataset.pkl", "rb"))
# Shuffle the data
X, Y = shuffle(X, Y)
# Make sure the data is normalized
img_prep = ImagePreprocessing()
img_prep.add_featurewise_zero_center()
img_prep.add_featurewise_stdnorm()
# Create extra synthetic training data by flipping, rotating and blurring the
# images on our data set.
img_aug = ImageAugmentation()
img_aug.add_random_flip_leftright()
img_aug.add_random_rotation(max_angle=25.)
img_aug.add_random_blur(sigma_max=3.)
# Define our network architecture:
# Input is a 32x32 image with 3 color channels (red, green and blue)
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
# Step 1: Convolution
network = conv_2d(network, 32, 3, activation='relu')
# Step 2: Max pooling
network = max_pool_2d(network, 2)
# Step 3: Convolution again
network = conv_2d(network, 64, 3, activation='relu')
# Step 4: Convolution yet again
network = conv_2d(network, 64, 3, activation='relu')
# Step 5: Max pooling again
network = max_pool_2d(network, 2)
# Step 6: Fully-connected 512 node neural network
network = fully_connected(network, 512, activation='relu')
# Step 7: Dropout - throw away some data randomly during training to prevent over-fitting
network = dropout(network, 0.5)
# Step 8: Fully-connected neural network with two outputs (0=isn't a bird, 1=is a bird) to make the final prediction
network = fully_connected(network, 2, activation='softmax')
# Tell tflearn how we want to train the network
network = regression(network, optimizer='adam',
loss='categorical_crossentropy',
learning_rate=0.001)
# Wrap the network in a model object
model = tflearn.DNN(network, tensorboard_verbose=0, checkpoint_path='bird-classifier.tfl.ckpt')
# Train it! We'll do 100 training passes and monitor it as it goes.
model.fit(X, Y, n_epoch=100, shuffle=True, validation_set=(X_test, Y_test),
show_metric=True, batch_size=96,
snapshot_epoch=True,
run_id='bird-classifier')
# Save model when training is complete to a file
model.save("bird-classifier.tfl")
print("Network trained and saved as bird-classifier.tfl!")역시 훈련을 시킬수록 정확도는 높아진다. 첫 번째 훈련 후에 75.4%의 정확도를 얻지만, 단 10회 훈련한 후 이미 91.7%까지 올라갔다. 50회 정도 지나면 95.5%의 정확도에 이르렀고 추가 훈련은 도움이 되지 않았기 때문에 멈추었다고 한다.
#5. 신경망 테스트 하기
이제 훈련된 신경망을 만들었고 바로 사용할 수 있다.
그러나 신경망이 얼마나 효과적인지를 실제로 확인하기 위해서는 아주 많은 이미지로 테스트해야 한다. 유효성 검사를 위해 15,000개의 이미지를 포함한 데이터 세트를 만들었다. 이 이미지를 실행해보니, 95% 수준으로 정확안 대답을 예측했다.
정확도 95%는 얼마나 정확한 것일까?
만약 훈련 이미지의 5%가 새이고 나머지 95%가 새가 아닌 경우, 매번 "새가 아니다"라고 추측하는 프로그램이 있다면 이것은 95% 정확한 것이 되지만 쓸모없는 신경망이 된다.
따라서 분류 시스템이 실제로 얼마나 좋은지 판단하기 위해서, 실패한 시간의 비율이 아니라 어떻게 실패했는지를 면밀히 조사해야 한다.
- 신경망이 올바르게 식별 한 새들 사진의 예. 이것을 맞힌 긍정(True Positives)라고 한다.

- "새가 아니다"라고 올바르게 식별 한 이미지들. 맞힌 부정(True Negatives)라고 한다.

- 새라고 생각했지만 실제 새가 아닌 이미지들. 틀린 긍정(False Positives)

- 정확하게 새로 인식하지 못한 이미지들. 틀린 부정(False Negatives)

15,000개 이미지의 유효성 검사 세트를 사용해서, 예측이 각 카테고리별로 어떻게 분류 되는지 알아보았다.

이렇게 세분화 하는 이유는 모든 실수가 같은 원인으로 발생하지 않기 때문이다.
따라서 평균적인 정확도를 보는 대신 Precision과 Recall을 계삲냈다.

위 결과는 97% 정확도로 "새"를 추측했음을 보여준다. 그러나 데이터 세트에서 실제 새의 90%만 발견했다는 사실도 알 수 있다. 바꿔 말하면 모든 새를 발견하지 못할 수도 있지만, 발견ㄴ했을 때는 꽤 확실하게 맞출 수 있다는 것이다.
'무지성 작업실 > WSS 세미나 - Face Recognition' 카테고리의 다른 글
| [정리] 기계학습(Machine Learning, 머신러닝)은 즐겁다! Part 4 (0) | 2021.09.08 |
|---|---|
| [정리] 기계학습(Machine Learning, 머신러닝)은 즐겁다! Part 2 (0) | 2021.09.04 |
| [정리] 기계학습(Machine Learning, 머신러닝)은 즐겁다! Part 1 (2) | 2021.09.04 |


