
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- CSS
- siss
- hackerrank
- c++
- HTML
- hackctf
- c
- PHP 웹페이지 만들기
- 풀이
- The Loard of BOF
- 숙명여자대학교 정보보안 동아리
- XSS Game
- 백준
- BOJ
- lob
- 기계학습
- BOJ Python
- 숙명여자대학교 정보보안동아리
- SWEA
- 생활코딩
- 드림핵
- Sookmyung Information Security Study
- 웹페이지 만들기
- Javascript
- 머신러닝
- C언어
- WarGame
- 자료구조 복습
- 파이썬
- Python
- Today
- Total
혜랑's STORY
2021 CodeEngn Conference 17 | 딥러닝으로 취약점을 찾아보자 본문
취약점 분석에 기계학습 응용
1. 하고싶었던 것
전체 소스코드가 주어질 때 각 함수가 어떤 취약점을 가지고 있을 확률이 몇 퍼센트인지 또한 다른 함수의 합류로 인해 그 확률이 개선되었는지 시각화 해준다.
2. Motivation
Automated Vulnerability Detection in Source Code Using Deep Representation Learning - IEEE 2018
선택 이유 : 데이터셋, 양질의 데이터를 확보하기 위해
3. Dataset
- csv 변환 : 판다스에서 다루기 쉽기 때문
- 중요한 특징
1) 각 데이터는 멀티 레이블을 갖는다.
2) 각 클래스별로 True/False 값을 가진다.
3) imbalanced : 학습 및 모델의 성능 평가때도 방해가 된다.
-> 학습할 때 특정 클래스의 데이터가 많아지게 되면 그 클래스에 관한 데이터는 잘 분류를 해내지만 다른 클래스에 대한 분류는 정확도가 낮아지게 된다.
-> 숫자로는 성능이 좋다고 평가될지라도 실제 분류에는 효과가 미미하다. 즉, 모델의 성능을 수치화하여 평가하기 어려움.
4. Model Selection
- 공간적인 정보를 종합하여 전체의 데이터에 다한 예측을 한다.
- 소스코드에게 순수한 정보 vs 공간적인 정보 둘 둥 어느게 더 중요할까? 정답은 없지만 생각해보면 취약점은 순차적으로 등장하는 것이 아니기 때문에 소스코드에는 공간적인 정보가 더 중요하다고 생각함.
5. Dataset Processing
- 파이썬 필로 라이브를 사용
- 텍스트 박스 속에 코드를 그대로 넣음

-> 사이즈가 굉장히 크게 나옴
-> cnn의 경우 데이터의 크기가 모두 동일해야 학습 성능이 올라감. 실제로 이미지 사이즈를 다 다르게 했을때 학습이 거의 되지 않던 것이 사이즈를 통일한 후 수월하게 학습됨
-> code2ming : 용량이 작아짐! 공백이 많아 학습에 방해가 될 것이라 예상했고 따라서 여백을 없애고 스케일링 함



-> token map : 소스코드를 원본 그대로 사용하는 것이 아니라 토큰으로 변환함
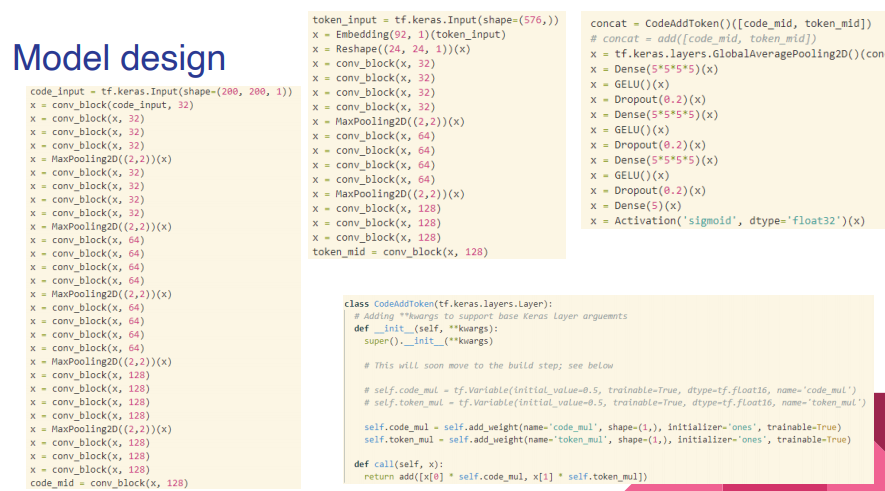
6. Model design

7. Training

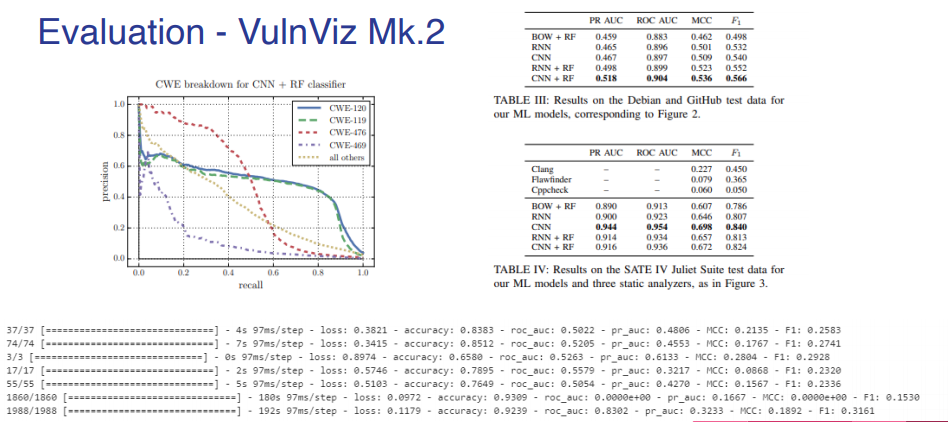
8. Evaluation


9. Final Result
